Triton-MLIR: Memory Coalesce
[toc]
Memory Coalesce是一个通用优化手段并不局限于Triton,以CUDA中访存通常会以一个Warp为单位进行,如果同一个Warp内多个线程的访存操作是连续的,那么这些访问就可以被coalesce,从而降低全局内存的访问开销。
但Triton和CUDA对于Memory Coalesce实现方式不同,前者是通过编译器Pass实现自动优化,而后者依赖于编写的CUDA Kernel,显然这两种方式各有利弊,由编译器Pass来做会更自动化,降低算子开发的难度,但同样在新架构特性出现后,其Pass也需要相应的改动以达到更优的性能。
免责声明:本人也是入门级选手,本篇是极其不完全的Triton解毒,后面会慢慢填坑,内容有任何问题请大家批评指正,谢谢!
关于GPU的访存模式,可以看下面几篇
CUDA编程学习笔记-03(内存访问) - 知乎 (zhihu.com)
1. Example
总体来说Triton中的Coalesce Pass主要做了以下几件事情。
For each memory op that has a layout L1: 1. Create a coalesced memory layout L2 of the pointer operands 2. Convert all operands from layout L1 to layout L2 3. Create a new memory op that consumes these operands and produces a tensor with layout L2 4. Convert the output of this new memory op back to L1 5. Replace all the uses of the original memory op by the new one
一段未Coalesce的TritonGPU IR
// RUN: triton-opt %s -tritongpu-coalesce
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1], threadsPerWarp = [32], warpsPerCTA = [4], order = [0], CTAsPerCGA = [1], CTASplitNum = [1], CTAOrder = [0]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1], CTAsPerCGA = [1, 1], CTASplitNum = [1, 1], CTAOrder = [0, 1]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [1, 4], order = [0, 1], CTAsPerCGA = [1, 1], CTASplitNum = [1, 1], CTAOrder = [0, 1]}>
#slice1dim1 = #triton_gpu.slice<{dim = 1, parent = #blocked1}>
#slice2dim0 = #triton_gpu.slice<{dim = 0, parent = #blocked2}>
module attributes {"triton_gpu.num-ctas" = 1 : i32, "triton_gpu.num-warps" = 4 : i32} {
tt.func @transpose(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32},
%arg1: i32 {tt.divisibility = 16 : i32},
%arg2: !tt.ptr<f32> {tt.divisibility = 16 : i32},
%arg3: i32 {tt.divisibility = 16 : i32}) {
%cst = arith.constant dense<true> : tensor<64x64xi1, #blocked1>
%cst_0 = arith.constant dense<0.000000e+00> : tensor<64x64xf32, #blocked1>
%00 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #slice1dim1>
%01 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #slice2dim0>
%1 = tt.expand_dims %00 {axis = 1 : i32} : (tensor<64xi32, #slice1dim1>) -> tensor<64x1xi32, #blocked1>
%2 = tt.splat %arg1 : (i32) -> tensor<64x1xi32, #blocked1>
%3 = arith.muli %1, %2 : tensor<64x1xi32, #blocked1>
%4 = tt.splat %arg0 : (!tt.ptr<f32>) -> tensor<64x1x!tt.ptr<f32>, #blocked1>
%5 = tt.addptr %4, %3 : tensor<64x1x!tt.ptr<f32>, #blocked1>, tensor<64x1xi32, #blocked1>
%6 = tt.expand_dims %01 {axis = 0 : i32} : (tensor<64xi32, #slice2dim0>) -> tensor<1x64xi32, #blocked2>
%7 = tt.broadcast %5 : (tensor<64x1x!tt.ptr<f32>, #blocked1>) -> tensor<64x64x!tt.ptr<f32>, #blocked1>
%8 = tt.broadcast %6 : (tensor<1x64xi32, #blocked2>) -> tensor<64x64xi32, #blocked2>
%9 = triton_gpu.convert_layout %8 : (tensor<64x64xi32, #blocked2>) -> tensor<64x64xi32, #blocked1>
%10 = tt.addptr %7, %9 : tensor<64x64x!tt.ptr<f32>, #blocked1>, tensor<64x64xi32, #blocked1>
%11 = tt.splat %arg2 : (!tt.ptr<f32>) -> tensor<64x1x!tt.ptr<f32>, #blocked1>
%12 = tt.addptr %11, %1 : tensor<64x1x!tt.ptr<f32>, #blocked1>, tensor<64x1xi32, #blocked1>
%13 = tt.splat %arg3 : (i32) -> tensor<1x64xi32, #blocked2>
%14 = arith.muli %6, %13 : tensor<1x64xi32, #blocked2>
%15 = tt.broadcast %12 : (tensor<64x1x!tt.ptr<f32>, #blocked1>) -> tensor<64x64x!tt.ptr<f32>, #blocked1>
%16 = tt.broadcast %14 : (tensor<1x64xi32, #blocked2>) -> tensor<64x64xi32, #blocked2>
%17 = triton_gpu.convert_layout %16 : (tensor<64x64xi32, #blocked2>) -> tensor<64x64xi32, #blocked1>
%18 = tt.addptr %15, %17 : tensor<64x64x!tt.ptr<f32>, #blocked1>, tensor<64x64xi32, #blocked1>
%19 = tt.load %10, %cst, %cst_0 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x64xf32, #blocked1>
tt.store %18, %19, %cst : tensor<64x64xf32, #blocked1>
tt.return
}
}上面代码第35,36行设计了访存操作,需要进行coalesce。
运行Pass后的结果
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [1, 4], order = [0, 1]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked3 = #triton_gpu.blocked<{sizePerThread = [4, 1], threadsPerWarp = [16, 2], warpsPerCTA = [1, 4], order = [0, 1]}>
module attributes {"triton_gpu.num-warps" = 4 : i32} {
func @transpose(%arg0: !tt.ptr<f32> {tt.divisibility = 16 : i32}, %arg1: i32 {tt.divisibility = 16 : i32}, %arg2: !tt.ptr<f32> {tt.divisibility = 16 : i32}, %arg3: i32 {tt.divisibility = 16 : i32}) {
%cst = arith.constant dense<0.000000e+00> : tensor<64x64xf32, #blocked0>
%cst_0 = arith.constant dense<true> : tensor<64x64xi1, #blocked0>
%0 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>
%1 = tt.make_range {end = 64 : i32, start = 0 : i32} : tensor<64xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>
%2 = tt.expand_dims %0 {axis = 1 : i32} : (tensor<64xi32, #triton_gpu.slice<{dim = 1, parent = #blocked0}>>) -> tensor<64x1xi32, #blocked0>
%3 = tt.splat %arg1 : (i32) -> tensor<64x1xi32, #blocked0>
%4 = arith.muli %2, %3 : tensor<64x1xi32, #blocked0>
%5 = tt.splat %arg0 : (!tt.ptr<f32>) -> tensor<64x1x!tt.ptr<f32>, #blocked0>
%6 = tt.addptr %5, %4 : tensor<64x1x!tt.ptr<f32>, #blocked0>, tensor<64x1xi32, #blocked0>
%7 = tt.expand_dims %1 {axis = 0 : i32} : (tensor<64xi32, #triton_gpu.slice<{dim = 0, parent = #blocked1}>>) -> tensor<1x64xi32, #blocked1>
%8 = tt.broadcast %6 : (tensor<64x1x!tt.ptr<f32>, #blocked0>) -> tensor<64x64x!tt.ptr<f32>, #blocked0>
%9 = tt.broadcast %7 : (tensor<1x64xi32, #blocked1>) -> tensor<64x64xi32, #blocked1>
%10 = triton_gpu.convert_layout %9 : (tensor<64x64xi32, #blocked1>) -> tensor<64x64xi32, #blocked0>
%11 = tt.addptr %8, %10 : tensor<64x64x!tt.ptr<f32>, #blocked0>, tensor<64x64xi32, #blocked0>
%12 = tt.splat %arg2 : (!tt.ptr<f32>) -> tensor<64x1x!tt.ptr<f32>, #blocked0>
%13 = tt.addptr %12, %2 : tensor<64x1x!tt.ptr<f32>, #blocked0>, tensor<64x1xi32, #blocked0>
%14 = tt.splat %arg3 : (i32) -> tensor<1x64xi32, #blocked1>
%15 = arith.muli %7, %14 : tensor<1x64xi32, #blocked1>
%16 = tt.broadcast %13 : (tensor<64x1x!tt.ptr<f32>, #blocked0>) -> tensor<64x64x!tt.ptr<f32>, #blocked0>
%17 = tt.broadcast %15 : (tensor<1x64xi32, #blocked1>) -> tensor<64x64xi32, #blocked1>
%18 = triton_gpu.convert_layout %17 : (tensor<64x64xi32, #blocked1>) -> tensor<64x64xi32, #blocked0>
%19 = tt.addptr %16, %18 : tensor<64x64x!tt.ptr<f32>, #blocked0>, tensor<64x64xi32, #blocked0>
%20 = triton_gpu.convert_layout %11 : (tensor<64x64x!tt.ptr<f32>, #blocked0>) -> tensor<64x64x!tt.ptr<f32>, #blocked2>
%21 = triton_gpu.convert_layout %cst_0 : (tensor<64x64xi1, #blocked0>) -> tensor<64x64xi1, #blocked2>
%22 = triton_gpu.convert_layout %cst : (tensor<64x64xf32, #blocked0>) -> tensor<64x64xf32, #blocked2>
%23 = tt.load %20, %21, %22 {cache = 1 : i32, evict = 1 : i32, isVolatile = false} : tensor<64x64xf32, #blocked2>
%24 = triton_gpu.convert_layout %23 : (tensor<64x64xf32, #blocked2>) -> tensor<64x64xf32, #blocked0>
%25 = triton_gpu.convert_layout %19 : (tensor<64x64x!tt.ptr<f32>, #blocked0>) -> tensor<64x64x!tt.ptr<f32>, #blocked3>
%26 = triton_gpu.convert_layout %24 : (tensor<64x64xf32, #blocked0>) -> tensor<64x64xf32, #blocked3>
%27 = triton_gpu.convert_layout %cst_0 : (tensor<64x64xi1, #blocked0>) -> tensor<64x64xi1, #blocked3>
tt.store %25, %26, %27 : tensor<64x64xf32, #blocked3>
return
}
}可以看到LoadOp的operands都从blocked0 -> blocked2。
#blocked0 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [32, 1], warpsPerCTA = [4, 1], order = [0, 1]}>
#blocked1 = #triton_gpu.blocked<{sizePerThread = [1, 1], threadsPerWarp = [1, 32], warpsPerCTA = [1, 4], order = [0, 1]}>
#blocked2 = #triton_gpu.blocked<{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [4, 1], order = [1, 0]}>
#blocked3 = #triton_gpu.blocked<{sizePerThread = [4, 1], threadsPerWarp = [16, 2], warpsPerCTA = [1, 4], order = [0, 1]}>对于Load和Store两个Op的处理大致相同,这里以LoadOp为例,看看coalesce pass是如何处理的。
void runOnOperation() override {
Operation *op = getOperation();
// Run axis info analysis
AxisInfoAnalysis axisInfo(&getContext());
axisInfo.run(op);
// For each i/o operation, we determine what layout
// the pointers should have for best memory coalescing
LayoutMap layoutMap;
op->walk([&](Operation *curr) {
Value ptr;
if (auto op = dyn_cast<triton::LoadOp>(curr))
ptr = op.ptr();
if (auto op = dyn_cast<triton::AtomicRMWOp>(curr))
ptr = op.ptr();
if (auto op = dyn_cast<triton::AtomicCASOp>(curr))
ptr = op.ptr();
if (auto op = dyn_cast<triton::gpu::InsertSliceAsyncOp>(curr))
ptr = op.src();
if (auto op = dyn_cast<triton::StoreOp>(curr))
ptr = op.ptr();
if (!ptr)
return;
RankedTensorType ty = ptr.getType().template dyn_cast<RankedTensorType>();
if (!ty || !ty.getElementType().isa<PointerType>())
return;
AxisInfo info = axisInfo.lookupLatticeElement(ptr)->getValue();
auto mod = curr->getParentOfType<ModuleOp>();
int numWarps = triton::gpu::TritonGPUDialect::getNumWarps(mod);
auto convertType = getTypeConverter(axisInfo, ptr, numWarps);
layoutMap[ptr] = convertType;
});
// For each memory op that has a layout L1:
// 1. Create a coalesced memory layout L2 of the pointer operands
// 2. Convert all operands from layout L1 to layout L2
// 3. Create a new memory op that consumes these operands and
// produces a tensor with layout L2
// 4. Convert the output of this new memory op back to L1
// 5. Replace all the uses of the original memory op by the new one
op->walk([&](Operation *curr) {
OpBuilder builder(curr);
if (auto load = dyn_cast<triton::LoadOp>(curr)) {
coalesceOp<triton::LoadOp>(layoutMap, curr, load.ptr(), builder);
return;
}
if (auto op = dyn_cast<triton::AtomicRMWOp>(curr)) {
coalesceOp<triton::AtomicRMWOp>(layoutMap, curr, op.ptr(), builder);
return;
}
if (auto op = dyn_cast<triton::AtomicCASOp>(curr)) {
coalesceOp<triton::AtomicCASOp>(layoutMap, curr, op.ptr(), builder);
return;
}
if (auto load = dyn_cast<triton::gpu::InsertSliceAsyncOp>(curr)) {
coalesceOp<triton::gpu::InsertSliceAsyncOp>(layoutMap, curr, load.src(),
builder);
return;
}
if (auto store = dyn_cast<triton::StoreOp>(curr)) {
coalesceOp<triton::StoreOp>(layoutMap, curr, store.ptr(), builder);
return;
}
});
}在MLIR中,每个Pass通常情况下都会重载runOnOperation方法,可以认为是每个pass的入口。
以上的逻辑比较直白,重点在于setCoalescedEncoding和coalesceOp方法。
2. 创建Data Layout
Attribute getCoalescedEncoding(AxisInfoAnalysis &axisInfo, Value ptr,
int numWarps) {
auto origType = ptr.getType().cast<RankedTensorType>();
// Get the shape of the tensor.
size_t rank = origType.getRank();
AxisInfo info = axisInfo.lookupLatticeElement(ptr)->getValue();
// Get the contiguity order of `ptr`
auto order = argSort(info.getContiguity());
// The desired divisibility is the maximum divisibility
// among all dependent pointers who have the same order as
// `ptr`
SetVector<Value> withSameOrder;
withSameOrder.insert(ptr);
if (ptr.getDefiningOp())
for (Operation *op : mlir::multiRootGetSlice(ptr.getDefiningOp())) {
for (Value val : op->getResults()) {
if (val.getType() != origType)
continue;
auto valInfo = axisInfo.lookupLatticeElement(val);
auto currOrder = argSort(valInfo->getValue().getContiguity());
if (order == currOrder)
withSameOrder.insert(val);
}
}
int numElems = product(origType.getShape());
int numThreads = numWarps * 32;
int numElemsPerThread = std::max(numElems / numThreads, 1);
// Thread tile size depends on memory alignment
SmallVector<unsigned, 4> sizePerThread(rank, 1);
unsigned elemNumBits = getPointeeBitWidth(origType);
unsigned elemNumBytes = std::max(elemNumBits / 8, 1u);
unsigned perThread = 1;
for (Value val : withSameOrder) {
AxisInfo info = axisInfo.lookupLatticeElement(val)->getValue();
unsigned maxMultipleBytes = info.getDivisibility(order[0]);
unsigned maxMultiple = std::max(maxMultipleBytes / elemNumBytes, 1u);
unsigned maxContig = info.getContiguity(order[0]);
unsigned alignment = std::min(maxMultiple, maxContig);
unsigned currPerThread = std::min(alignment, 128 / elemNumBits);
perThread = std::max(perThread, currPerThread);
}
sizePerThread[order[0]] = std::min<int>(perThread, numElemsPerThread);
SmallVector<unsigned> dims(rank);
std::iota(dims.begin(), dims.end(), 0);
// create encoding
Attribute encoding = triton::gpu::BlockedEncodingAttr::get(
&getContext(), origType.getShape(), sizePerThread, order, numWarps);
return encoding;
}Trtion优先处理Contiguity长的维度,用order来表示优先处理哪一维度,如contiguity = [1, 64],那么order = [1, 0]
那如何计算contiguity呢?
AxisInfo info = axisInfo.lookupLatticeElement(ptr)->getValue();显然逻辑是写在了Axis Analysis,利用数据流分析的方法计算出axisInfo(死去的程序分析知识疯狂向我攻击)
暂时没有看明白细节,但大致是计算operand的gcd,属于join操作,从前往后看,LoadOp的operand是从%7传播过来的,而%7的contiguity = [64, 1],即时%10是[64, 64],经过前向的join操作也会变成[64, 1],从而可以得出应该先处理dim1,也即order应为[1, 0]
通过Axis Analysis后,我们得到了想要的Contiguity,Divisibility信息,用于计算order及后续sizePerThread等分布。
order如何计算的? 原则是比较每个维度的contiguity,谁大谁就先处理。
解决了order的计算问题,接着来看,如何计算sizePerThread,也即每个线程要处理多少个元素
一个方法是直接用numElems / numThreads计算,但显然这个计算方法没有考虑GPU的访存模式。
计算sizePerThread这里的逻辑其实已经和上文中引用的几篇文章大致相同了,需要先算出ptr所指的数据类型位宽,进而通过aligment,contiguity等参数计算最终结果。
得到sizePerThread后,由于处理的是2D矩阵,所以sizePerThread也是二维的,最终sizePerThread = [1, 4]。
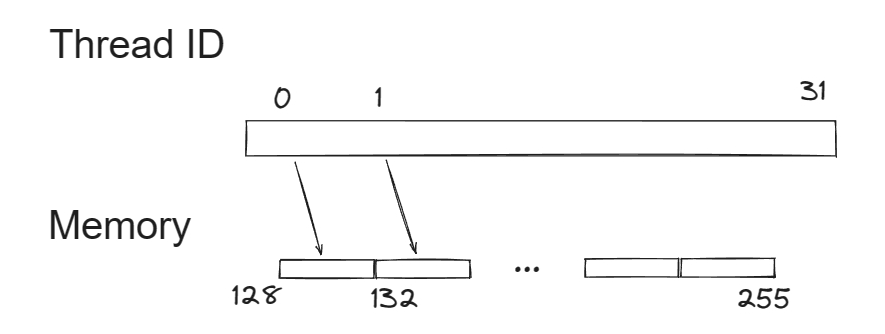
这里仅是示意图,线程在一个Warp中的分布也会是2D。
OK,解决了sizePerThread后,其他参数的确定是由BlockedEncodingAttr的get方法确定的,该类由MLIR-tablegen自动生成。
auto CTALayout = triton::gpu::getCTALayout(refTensorType.getEncoding());
layoutMap[op] = triton::gpu::BlockedEncodingAttr::get(
&getContext(), refTensorType.getShape(), sizePerThread, order, numWarps,
threadsPerWarp, CTALayout);BlockedEncodingAttr BlockedEncodingAttr::get(::mlir::MLIRContext *context, ArrayRef<int64_t> shape, ArrayRef<unsigned> sizePerThread, ArrayRef<unsigned> order, unsigned numWarps, unsigned numThreadsPerWarp, CTALayoutAttr CTALayout) {
unsigned rank = sizePerThread.size();
SmallVector<unsigned, 4> threadsPerWarp(rank);
SmallVector<unsigned, 4> warpsPerCTA(rank);
SmallVector<int64_t> shapePerCTA = getShapePerCTA(CTALayout.getCTASplitNum(), shape);
unsigned remainingLanes = numThreadsPerWarp;
unsigned remainingThreads = numWarps * numThreadsPerWarp;
unsigned remainingWarps = numWarps;
unsigned prevLanes = 1;
unsigned prevWarps = 1;
// starting from the contiguous dimension
for (unsigned d = 0; d < rank - 1; ++d) {
unsigned i = order[d];
unsigned threadsPerCTA = std::clamp<unsigned>(remainingThreads, 1, shapePerCTA[i] / sizePerThread[i]);
threadsPerWarp[i] = std::clamp<unsigned>(threadsPerCTA, 1, remainingLanes);
warpsPerCTA[i] = std::clamp<unsigned>(threadsPerCTA / threadsPerWarp[i], 1, remainingWarps);
remainingWarps /= warpsPerCTA[i];
remainingLanes /= threadsPerWarp[i];
remainingThreads /= threadsPerCTA;
prevLanes *= threadsPerWarp[i];
prevWarps *= warpsPerCTA[i];
}
// Expand the last dimension to fill the remaining lanes and warps
threadsPerWarp[order[rank - 1]] = numThreadsPerWarp / prevLanes;
warpsPerCTA[order[rank - 1]] = numWarps / prevWarps;
return Base::get(context, sizePerThread, threadsPerWarp, warpsPerCTA, order, CTALayout);
}这段代码会自动计算出threadsPerWarp和warpsPerCTA,即warp中线程的分布和CTA中warp的分布,画个图理解一下
{sizePerThread = [1, 4], threadsPerWarp = [2, 16], warpsPerCTA = [4, 1], order = [1, 0]}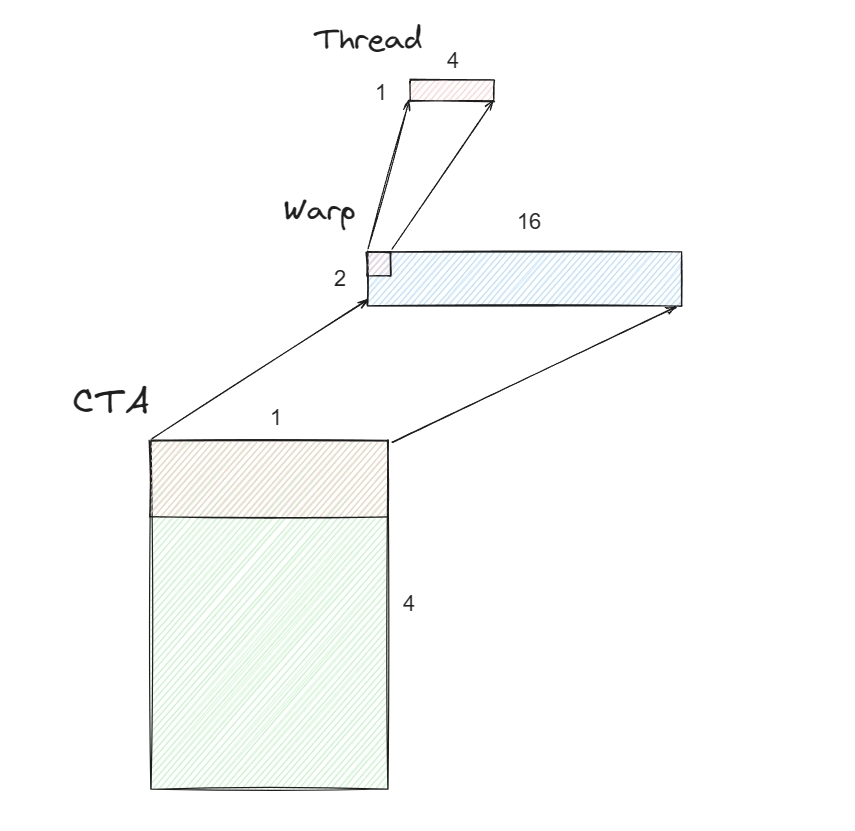
3. 创建新Ops
到目前为止,已经成功生成了新的Data Layout,那么下一步就是如何生成一些convertLayoutOp,用于将operand的layout变换为new layout
template <class T>
void coalesceOp(LayoutMap &layoutMap, Operation *op, Value ptr,
OpBuilder builder) {
RankedTensorType ty = ptr.getType().template dyn_cast<RankedTensorType>();
if (!ty)
return;
auto convertType = layoutMap.lookup(ptr);
// convert operands
SmallVector<Value, 4> newArgs;
for (auto v : op->getOperands()) {
auto vTy = v.getType().dyn_cast<RankedTensorType>();
if (vTy && !vTy.getEncoding().isa<triton::gpu::SharedEncodingAttr>())
newArgs.push_back(builder.create<triton::gpu::ConvertLayoutOp>(
op->getLoc(), convertType(v.getType()), v));
else
newArgs.push_back(v);
}
// convert output types
SmallVector<Type, 4> newTypes;
for (auto t : op->getResultTypes()) {
bool is_async = std::is_same<T, triton::gpu::InsertSliceAsyncOp>::value;
newTypes.push_back(is_async ? t : convertType(t));
}
// construct new op with the new encoding
Operation *newOp =
builder.create<T>(op->getLoc(), newTypes, newArgs, op->getAttrs());
// cast the results back to the original layout
for (size_t i = 0; i < op->getNumResults(); i++) {
Value newResult = newOp->getResult(i);
if (newTypes[i] != op->getResultTypes()[i]) {
newResult = builder.create<triton::gpu::ConvertLayoutOp>(
op->getLoc(), op->getResult(i).getType(), newResult);
}
op->getResult(i).replaceAllUsesWith(newResult);
}
op->erase();
}第一个for循环为每个operand都创建一个ConvertLayoutOp,接着重新生成LoadOp,并在结尾删掉原来的LoadOp,LoadOp创建后,最后一个for循环再将他们都转换到原来的Layout。
至此,整个Pass运行完毕生成了上面的IR结果。



