鸢尾花分类
iris 数据集包含 150 个样本,对应数据集的每行数据。每行数据包含每个 样本的四个特征和样本的类别信息,iris 数据集是用来给鸢尾花做分类的数据集, 每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征,请用神经 网络训练一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、 变色鸢尾还是维吉尼亚鸢尾。数据集文件 iris.csv。要求模型准确率不低于 99%。
1.准备数据
import torch
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader, TensorDataset
from sklearn.utils import shuffledef gen_data(file):
data = pd.read_csv(file)
# 打上label
for i in range(len(data)):
if data.loc[i, 'Species'] == 'setosa':
data.loc[i, 'Species'] = 0
elif data.loc[i, 'Species'] == 'versicolor':
data.loc[i, 'Species'] = 1
else:
data.loc[i, 'Species'] = 2
data = data.drop('Unnamed: 0', axis=1)
data = shuffle(data)
data.index = range(len(data))
# 归一化
col_titles = ['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']
for i in col_titles:
mean, std = data[i].mean(), data[i].std()
data[i] = (data[i] - mean) / std
train_data = data[: -32]
train_x = train_data.drop(['Species'], axis=1).values
train_y = train_data['Species'].values.astype(int)
train_x = torch.from_numpy(train_x).type(torch.FloatTensor)
train_y = torch.from_numpy(train_y).type(torch.LongTensor)
test_data = data[-32: ]
test_x = test_data.drop(['Species'], axis=1).values
test_y = test_data['Species'].values.astype(int)
test_x = torch.from_numpy(test_x).type(torch.FloatTensor)
test_y = torch.from_numpy(test_y).type(torch.LongTensor)
train_dataset = TensorDataset(train_x, train_y)
test_dataset = TensorDataset(test_x, test_y)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
return train_loader, test_loader 2.构建模型
因为鸢尾花有四个特征,三个类别,所以构造模型如下
class model(torch.nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(4, 5) # 四个特征
self.out = nn.Linear(5, 3) # 三个类别
def forward(self, x):
x = self.hidden(x)
x = F.relu(x)
x = self.out(x)
return x 3.训练模型
def train(net, loss_func, opt, epochs, train_loader):
losses = []
for epoch in range(epochs):
batch_loss = []
for i, data in enumerate(train_loader):
x, y = data
pred = net(x)
loss = loss_func(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
batch_loss.append(loss.detach().numpy())
losses.append(np.mean(batch_loss))
if epoch % 100 == 0:
print("loss: ", loss)
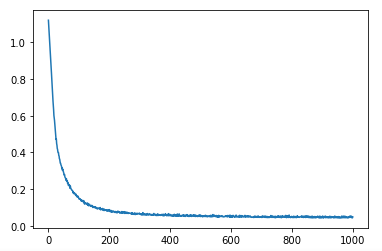
plt.plot(np.arange(epochs), losses)
plt.show()net = model()
loss_func = nn.CrossEntropyLoss()
opt = torch.optim.SGD(net.parameters(), lr=0.05)
epochs = 1000
train_loader, test_loader = gen_data('iris.csv')
train(net, loss_func, opt, epochs, train_loader)这里的损失函数,选择的是交叉熵损失函数,其自带sofmax层,可以串接在最后一层全连接输出后,达到分类效果
4.预测结果
def prediction(net, test_loader):
rights = 0
length = 0
for i, data in enumerate(test_loader):
x, y = data
pred = net(x)
rights += rightness(pred, y)[0]
length += rightness(pred, y)[1]
print('labels: ', y)
print('pred: ', torch.max(pred, 1)[1], '\n')
print("acc: ", rights / length * 100)
def rightness(pred, labels):
pred = torch.max(pred, 1)[1]
rights = pred.eq(labels).sum()
return rights, len(labels)
prediction(net, test_loader)



