共享单车预测
通过历史数据预测某一地区接下来一段时间内的共享单车的数量。数据保存在文件 bikes.csv 中,请按 11:1 的比例划分训练集和测试集,首先对数据进 行预处理,然后在训练集上训练,并在测试集上验证模型。设计神经网络数据进行拟合,利用训练后的模型对数据拟合并进行预测,记录误差,并绘制出拟合效果。
1.准备数据
import torch
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt
import pandas as pd生成数据集
def gen_data(file):
data = pd.read_csv(file)
# one-hot编码
col_titles = ['season', 'weathersit', 'mnth', 'hr', 'weekday']
for i in col_titles:
# 生成形如season_0, season_1的列
dummies = pd.get_dummies(data[i], prefix=i)
data = pd.concat([data, dummies], axis=1)
# 删除列
col_titles_to_drop = ['instant', 'dteday', 'season', 'weathersit', 'weekday', 'mnth', 'workingday', 'hr']
data = data.drop(col_titles_to_drop, axis=1)
# 归一化
col_titles = ['cnt', 'temp', 'hum', 'windspeed']
for i in col_titles:
mean, std = data[i].mean(), data[i].std()
if i == 'cnt':
mean_cnt, std_cnt = mean, std
data[i] = (data[i] - mean) / std
print(len(data))
# 划分训练集和测试集11:1,`cnt`是label
train_data = data[: -len(data) // 12]
print(len(train_data))
train_value = train_data['cnt']
train_data = train_data.drop(['cnt'], axis=1).values
train_value = train_value.values.astype(float).reshape(-1, 1)
test_data = data[-len(data) // 12 : ]
print(len(test_data))
test_value = test_data['cnt']
test_data = test_data.drop(['cnt'], axis=1).values
test_value = test_value.values.astype(float).reshape(-1, 1)
return train_data, train_value, test_data, test_value, mean_cnt, std_cnt2.构建模型
train_data, train_value, test_data, test_value, mean_cnt, std_cnt = gen_data('bikes.csv')
input_size = train_data.shape[1] # 特征(列数)
hidden_size = 10
output_size = 1
net = torch.nn.Sequential(torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size))3.训练模型
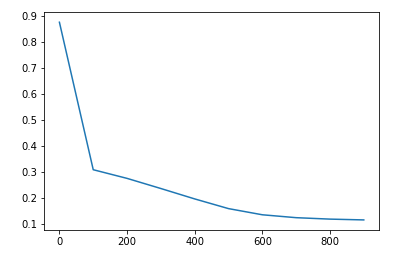
def train(train_data, train_value, net, loss_func, opt, epochs):
losses = []
for i in range(epochs):
batch_loss = []
for start in range(0, len(train_data), batch_size):
if start + batch_size < len(train_data):
end = start + batch_size
else:
end = len(train_data)
x = torch.FloatTensor(train_data[start : end])
y = torch.FloatTensor(train_value[start : end])
pred = net(x)
loss = loss_func(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
batch_loss.append(loss.detach().numpy())
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
plt.plot(np.arange(len(losses)) * 100, losses)
plt.show()
loss_func = torch.nn.MSELoss()
opt = torch.optim.SGD(net.parameters(), lr = 0.01)
epochs = 1000
batch_size = 128
train(train_data, train_value, net, loss_func, opt, epochs)这里没有用到加载器,DataLoader,而是手动划分了batch,并且能很好的对最后的批次进行处理(有可能不整除)
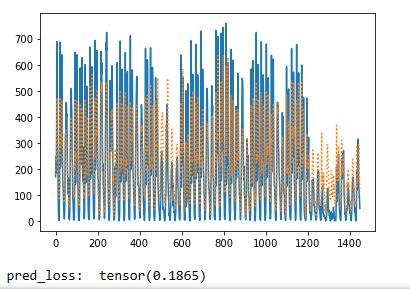
4.预测结果
def prediction(test_data, test_value, net, mean, std):
x = torch.FloatTensor(test_data)
y = torch.FloatTensor(test_value)
pred = net(x)
with torch.no_grad():
loss = loss_func(pred, y)
pred = pred.detach().numpy() * std + mean
y = y.detach().numpy() * std + mean
plt.plot(np.arange(x.shape[0]), y)
plt.plot(np.arange(x.shape[0]), pred, ':')
plt.show()
print("pred_loss: ", loss)
prediction(test_data, test_value, net, mean_cnt, std_cnt)由于数据经过归一化,现在需要通过mean和std将数据还原回去