CIFAR-10分类网络
通过 CIFAR-10 数据集训练得到一个彩色图像分类网络。要求设计一 个至少包含 5 个卷积层和池化层的卷积神经网络。卷积核的尺寸统一采用 3*3, 要求训后的得到的网络在测试集上的准确率不低于 70%(要求在网络中使用 BatchNorm)
1.准备数据
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import torch.nn as nn
import torch. nn.functional as F
from torch.utils.data import Dataset, DataLoader, TensorDataset
import matplotlib.pyplot as plt
import numpy as np
import time
from torch.utils.data.sampler import SubsetRandomSamplertrain_data = datasets.CIFAR10(root='./',
train=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]),
download=True
)
test_data = datasets.CIFAR10(root='./',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
)
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(0.2 * num_train))
train_idx, valid_idx = indices[split:], indices[:split]
# define samplers for obtaining training and validation batches
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
train_loader = DataLoader(dataset=train_data, batch_size=64, sampler=train_sampler, num_workers=8)
valid_loader = DataLoader(dataset=train_data, batch_size=64, sampler=valid_sampler, num_workers=8)
test_loader = DataLoader(dataset=test_data, batch_size=64, num_workers=8)构建模型
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.conv3 = nn.Conv2d(32, 64, 3, padding=1)
self.conv4 = nn.Conv2d(64, 64, 3, padding=1)
self.conv5 = nn.Conv2d(64, 64, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.bn2 = nn.BatchNorm2d(32)
self.bn3 = nn.BatchNorm2d(64)
self.bn4 = nn.BatchNorm2d(64)
self.bn5 = nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 1 * 1, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv3(x)
x = self.bn3(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv4(x)
x = self.bn4(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv5(x)
x = self.bn5(x)
x = F.relu(x)
x = self.pool(x)
x = x.view(-1, 64 * 1 * 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x用BN代替dropout
3.训练模型
def train(train_loader, valid_loader, net, loss_func, opt, epochs):
valid_loss_min = np.Inf
start = time.time()
train_loss_list = []
valid_loss_list = []
for epoch in range(epochs):
train_loss = 0.0
valid_loss = 0.0
net.train()
for x, y in train_loader:
x = x.cuda()
y = y.cuda()
pred = net(x)
loss = loss_func(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
train_loss += loss.item() * x.size(0)
net.eval()
for x, y in valid_loader:
x = x.cuda()
y = y.cuda()
pred = net(x)
loss = loss_func(pred, y)
valid_loss += loss.item() * x.size(0)
# 计算平均损失
train_loss = train_loss/len(train_loader.sampler)
valid_loss = valid_loss/len(valid_loader.sampler)
train_loss_list.append(train_loss)
valid_loss_list.append(valid_loss)
# 显示训练集与验证集的损失函数
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch, train_loss, valid_loss))
# 如果验证集损失函数减少,就保存模型。
if valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,valid_loss))
torch.save(net.state_dict(), 'model_cifar.pt')
valid_loss_min = valid_loss
print('spend_time: ', time.time() - start)
plt.plot(np.arange(epochs), train_loss_list, 'r', label='train')
plt.plot(np.arange(epochs), valid_loss_list, 'b', label='valid')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()cnn = model().cuda()
loss_func = nn.CrossEntropyLoss()
opt = torch.optim.SGD(cnn.parameters(), lr = 0.01, momentum=0.9)
epochs = 10
train(train_loader, valid_loader, cnn, loss_func, opt, epochs)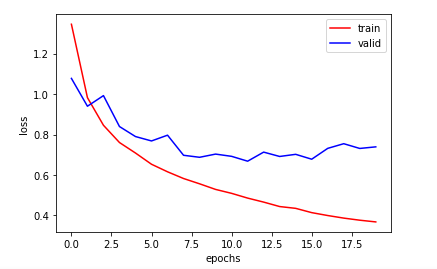
使用验证集,可挑选泛化能力更好的模型
4.预测结果
def prediction(test_loader, net):
rights = 0
length = 0
for i, data in enumerate(test_loader):
x, y = data
x = x.cuda()
y = y.cuda()
pred = net(x)
rights += rightness(pred, y)[0]
length += rightness(pred, y)[1]
print(rights / length)
def rightness (pred, labels):
pred = torch.max(pred.data, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
cnn.load_state_dict(torch.load('model_cifar.pt'))
prediction(test_loader, cnn)



